Alerts
Telemetry alerts let you monitor query output and get notified by email when a metric crosses a threshold.
How alerts work
Each alert evaluation follows the same flow:
- Run the saved query (from Explore or a SQL query).
- Order rows by timestamp (newest first).
- Optionally ignore the latest row (
Ignore the last data point). - Take the last
Ndata points. - Compute an aggregation (
avg,sum,p95, etc.). - Compare the value to your threshold.
- Send notifications when state changes (triggered or resolved).
Create an alert from Explore
- Open
/team/{team}/table/{table}?tab=explore. - Set graph type, filters, time range, and metric.
- Click Run.
- In the results toolbar above the chart, click Create Alert.
- Configure condition, interval, and recipients.
- Click Create Alert to save.
After you run an Explore query, the alert button appears on the right side of the results toolbar next to Add to Dashboard:
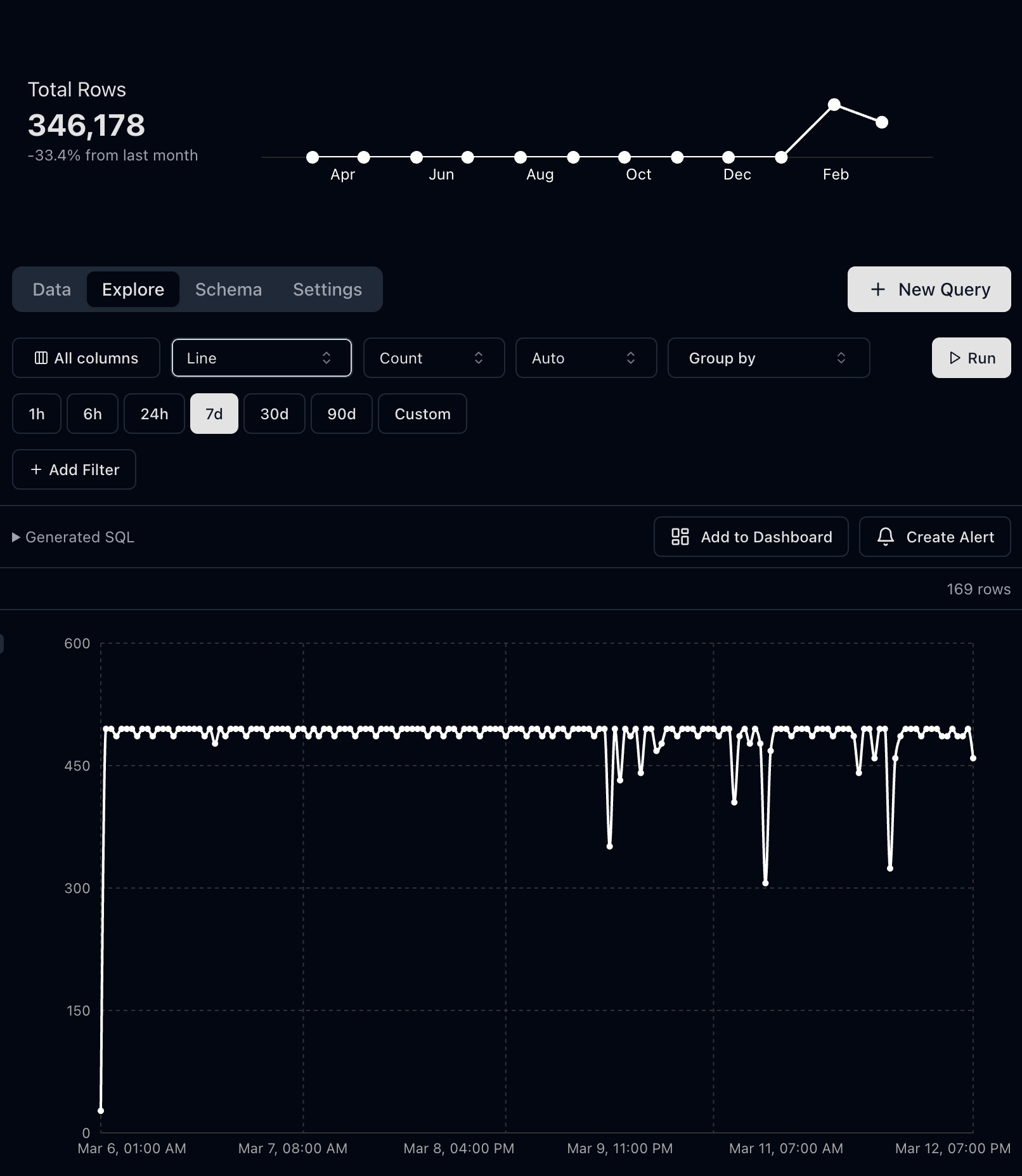
Use Create Alert from the results toolbar after clicking Run.
After creation, you will land on /team/{team}/alert/{alertSlug} where you can inspect status and event history.
Create an alert from SQL query results
- Open a saved query.
- Run the query and switch to Results or Chart tab.
- Click Create Alert.
- Choose aggregation and threshold logic.
- Save and verify the alert detail page.
Alert condition fields
| Field | Meaning |
|---|---|
| Aggregation | How values are reduced (avg, max, p95, etc.) |
| Last N data points | Window size for evaluation |
| Ignore last data point | Skips newest row to avoid incomplete buckets |
| Comparison | >, >=, <, <= |
| Threshold | Numeric target for the comparison |
| Check interval | How often the evaluator runs |
| Recipients | Email addresses for notifications |
Interactive inline examples
Example 1: API latency regression (p95)
Open this Explore URL template and replace placeholders:
/team/{team}/table/{table}?tab=explore&graphType=line&agg=p95&metric=latency_ms&time=7dThen create an alert with:
- Aggregation:
p95 - Last N points:
5 - Comparison:
Greater than - Threshold:
850 - Interval:
Every minute
Example 2: Error surge detector
Run this query in your SQL editor:
SELECT
date_trunc('minute', timestamp_utc) AS time_bucket,
COUNT(*) AS errors
FROM
http_logs
WHERE
status_code >= 500
AND timestamp_utc >= now() - INTERVAL '2 hours'
GROUP BY
time_bucket
ORDER BY
time_bucket DESC;Create an alert:
- Metric:
errors - Aggregation:
avg - Last N points:
3 - Comparison:
Greater than - Threshold:
20
Example 3: Missing traffic detector
Use this when event volume unexpectedly drops:
- Build a chart or query that returns event counts over time.
- Create an alert using
sumover the last10points. - Set comparison to
Less thanand threshold to50.
If triggered, check ingestion services, queues, and cron workers.
Troubleshooting
- No notifications: verify recipient emails are valid and alert is enabled.
- False positives: increase
Last N data pointsor keepIgnore last data pointenabled. - Alert never triggers: lower threshold or confirm the selected metric column is numeric.